
Uczenie modelu i wnioskowanie jedynie na podstawie wyniku na zbiorze danych, na którym uczymy (tak jak w poście "Sieci konwolucyjne") jest krótkowzroczne. Oczywiście, model uruchomiony na dokładnie tych danych będzie działać wzorowo; jednakże szybko okaże się, że nie ma zastosowania w praktyce, gdyż jego zdolność generalizacji będzie mała. Należy przyjąć strategię jak testować postęp nauki, żeby wyciągać właściwe wnioski na temat jakości modelu.
[Ten post jest fragmentem serii "Krok po kroku" wprowadzającej do uczenia maszynowego (Machine Learning). Zapraszam do zapoznania się z całością.]
Opis sposobu
Standardowym podejściem jest podział zbioru danych, jaki mamy do dyspozycji na trzy części:
- zbiór uczący ("train" od ang. training )
- zbiór walidacyjny ("val" - od ang. validation)
- zbiór testowy ("test" - od ang. test)
Rozmiary zbiorów
W zależności od wielkości początkowego zbioru, jaki mamy przeznaczony na potrzeby uczenia zadecydować należy w jakich proporcjach podzielić go na podzbiory.
"Train"
Główną potrzebą uczenia jest posiadanie dużej ilości danych, możliwie różnorodnych by wyuczony model mial zdolności generalizowania zebranej wiedzy. Dlatego zbiór testowy powinien być największy. "Standardem" jest tutaj 80%.
"Val"
Zadaniem zbioru walidacyjnego jest sprawdzenie czy model nie "przeucza się" (nie zaczyna zapamiętywać zbiory treningowego, zamiast generalizować wiedzę). Po każdej epoce uczenia sprawdzany jest wynik na zbiorze walidacyjnym i generalną zasadą jest, że dąży się do jego optymalizacji. Kiedy wynik na zbiorze walidacyjnym nie poprawia się, najpewniej jest to oznaką, że przy zadanych warunkach uczenia nie ma lepszej możliwości generalizacji. Zwykle jest to 10% początkowego zbioru.
"Test"
Po zakończeniu treningu i wybraniu najlepszego modelu na podstawie obserwacji wyniku na zbiorze walidacyjnym przydatny jest zbiór testowy. Używany jest po to aby upewnić się, czy optymalizacja wyniku zbioru walidayjnego nie była "szczęśliwym trafem" (być może spowodowanym wieloma epokami uczenia bez wyraźnego progresu
Dlaczego?
Jak już powyżej zostało wspomniane, celem podziału zbioru jest upewnienie się, że model nie zapamiętuje przykładów uczących zamiast wyciągać z nich ogólną wiedzę. Powszechnie wiadomo, że sieci konwolucyjne mają tendencję to zapamiętywania schematów, które pozwalają im skuteczniej spełniać kryteria funkcji kosztu. Istnieje wiele metod, które mają temu zaradzić a podział zbioru ma by potwierdzeniem, że owo zapamiętywanie nie ma miejsca. Niemniej, nie jest to pewnik, ale bardzo dobre przybliżenie.
Kod
Do dzielenia zbioru w kodzie Pythona najczęściej używana jest biblioteka scikit-learn.
Dzielenie zbioru
from sklearn.model_selection import train_test_split
X = [1,2,3,4,5,6,7,8,9,10]
y = [10,20,30,40,50,60,70,80,90,100]
train_size_percent = 0.8
random_state = 1024
X_train, X_testval, y_train, y_testval = train_test_split
(X, y,
test_size=1-train_size_percent,
random_state=random_state)
X_test, X_val, y_test, y_val = train_test_split
(X_testval, y_testval,
test_size=0.5,
random_state=random_state)
del X_testval, y_testval
print("X_train:", X_train, "y_train:", y_train)
print("X_val:", X_val, "y_val:", y_val)
print("X_test:", X_test, "y_test:", y_test)Powyższy kod wyświetla:
X_train: [8, 1, 7, 9, 6, 5, 10, 2] y_train: [80, 10, 70, 90, 60, 50, 100, 20]
X_val: [3] y_val: [30]
X_test: [4] y_test: [40]Użycie zbiorów w Kerasie
Kiedy model jest stworzony (jak na przykład tutaj), aby dodać walidację po każdej epoce wystarczy dodać parametr "validation_data" w funkcji "fit" ze wskazaniem odpowiednich danych:
model.fit(X_train, y_train,
validation_data= (X_val, y_val),
batch_size=16, epochs=150)Wykresy i interpretacja
Spójrzmy na wybrane wykresy zaczynając od funkcji kosztu dla wybranych przedziałów epok uczenia (80 do 140):
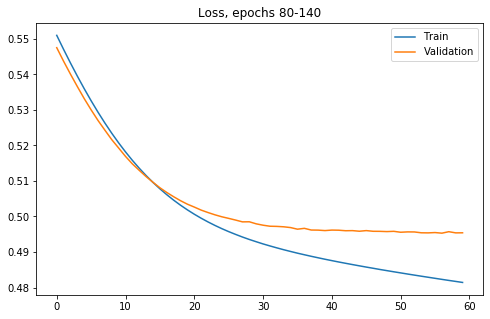
Widać, że na zbiorze treningowym funkcja kosztu dla zbioru treningowego ciągle maleje, niemniej od epoki około 13 (dokładnie 80+13) różnice wyniku pomiędzy zbiorem treningowym i walidacyjnym zaczynają odstawać. Zobaczmy jak wpływa to na celność modelu:
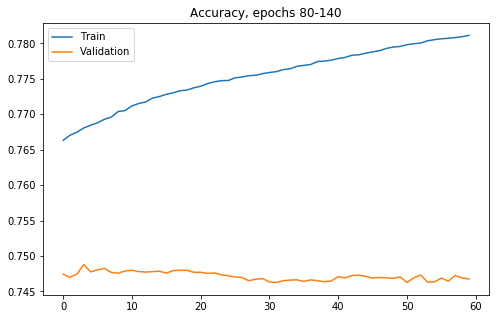
Tutaj obserwujemy wzrost wartości metryki na zbiorze treningowym, co nie przekłada się na wynik na próbkach do tej pory nie widzianych. Można podejrzewać, że zamiast uczyć się ogólnych zasad rozpoznawania obrazu model zaczyna coraz lepiej zapamiętywać zbiór treningowy. Przyglądnijmy się jeszcze dokładniej celności na samym zbiorze walidacyjnym (różnice na powyższym wykresie niedokładnie pokazują zachowanie trendu):
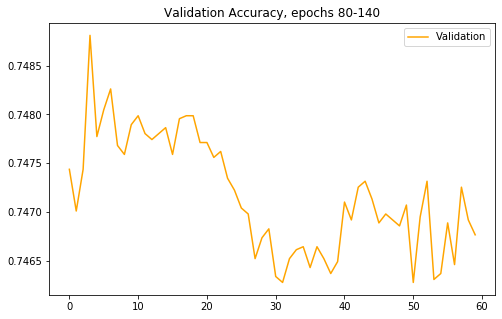
Widać, że maksimum wartości było uzyskane zdecydowanie wcześniej niż w ostatniej epoce.
Zapisywanie najlepszego wyniku
W Keras (TensorFlow) są dwie metody, które usprawnią naszą pracę w tym zagadnieniu.
Po pierwsze: Zapisywanie najlepszego modelu - realizowane przez callback (jako parametr przekazujemy funkcję odpowiedzialną za zapisywanie najlepszego modelu):
callbacks=[
keras.callbacks.ModelCheckpoint("best.h5",save_best_only=True)
]
fit_result = model.fit(X_train, y_train,
validation_data= (X_val, y_val),
batch_size=16, epochs=150
callbacks=callbacks)Drugim zagadnieniem jest "EarlyStopping". Skoro wiadomo, ze istnieje epoka, od której funkcji kosztu na zbiorze walidacyjnym zaczynaj maleć, można oszczędzić sobie czasu i zakonczyć naukę jeżeli wynik nie poprawia się przez X kolejnych epok.
Załatwiamy to podobnie prostym kodem:
# Train
callbacks=[
keras.callbacks.EarlyStopping(patience=3),
]
fit_result = model.fit(X_train, y_train,
validation_data= (X_val, y_val),
batch_size=16, epochs=150
callbacks=callbacks)W powyższym przykładzie "cierpliwość" jest ustawiona na 3 co oznacza, że po 3 epokach bez poprawienia funkcji kosztu na zbiorze walidacyjnym, trening modelu zakończy się.
Więcej...
W dalszych postach ukażą się także tematy bezpośrednio związane z tematyką dzielenia zbioru:
- dzielenie niezbalansowanego zbioru uczącego
- walidacja krzyżowa (cross-validation)
- bias ("obciążenie" dataset-u)
- augmentacja danych - metoda na lepszą generalizację