
Ten post pokazuje jak inna koncepcja niż gęste połączenie neuronów w kolejnych warstwach sieci neuronowej może znacząco poprawić rezultaty klasyfikacji obrazów.
Punktem odniesienia tego posta jest poprzedni - "Binarna klasyfikacja obrazów" (tam znajdziesz też kod służący do wczytania danych i przeprowadzenia treningu).
Dziś skupimy się na zrozumieniu operacji realizowanej przez warstwę konwolucyjną.
[Ten post jest fragmentem serii "Krok po kroku" wprowadzającej do uczenia maszynowego (Machine Learning). Zapraszam do zapoznania się z całością.]
Konwolucja 2D
Operacja konwolucji to przekształcenie macierzowe fragmentów zdjęcia mające na celu wydobycie informacji o cechach obrazu. Operacja to od wielu lat wykorzystywana była przykładowo do wykrywania krawędzi w obrazach.
Macierz przetwarzająca obraz aplikowana jest na fragmentach zdjęcia odpowiadającej jej wielkości. Do wyniku brany jest wynik przemnożenia korespondujących elementów macierzy. Świetnie to widać na poniższej wizualizacji:
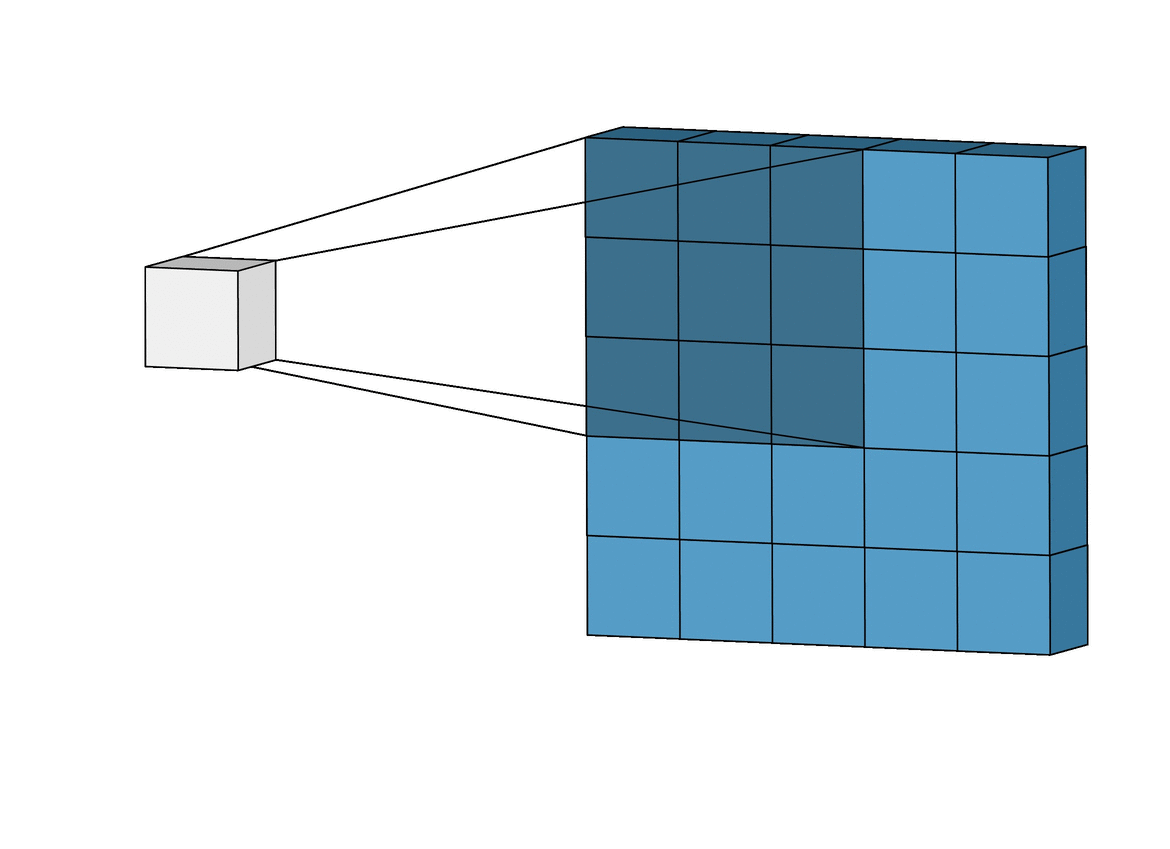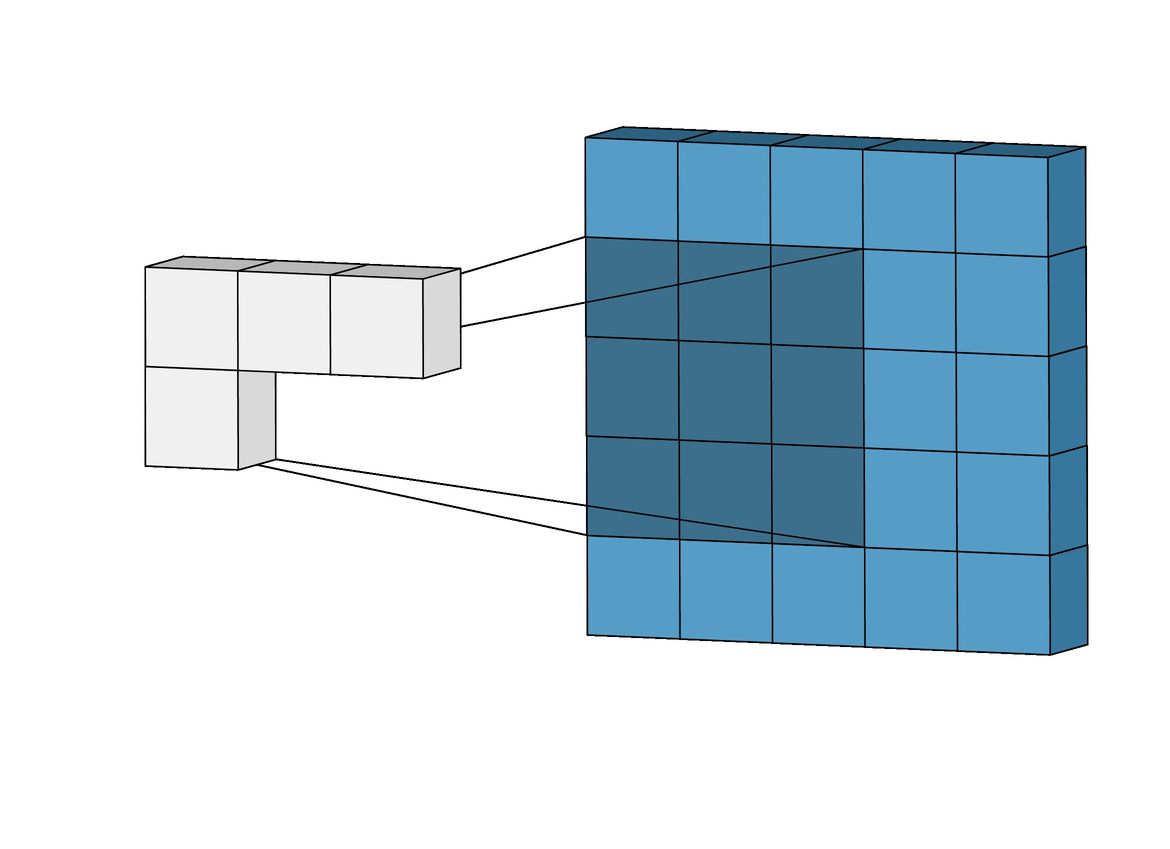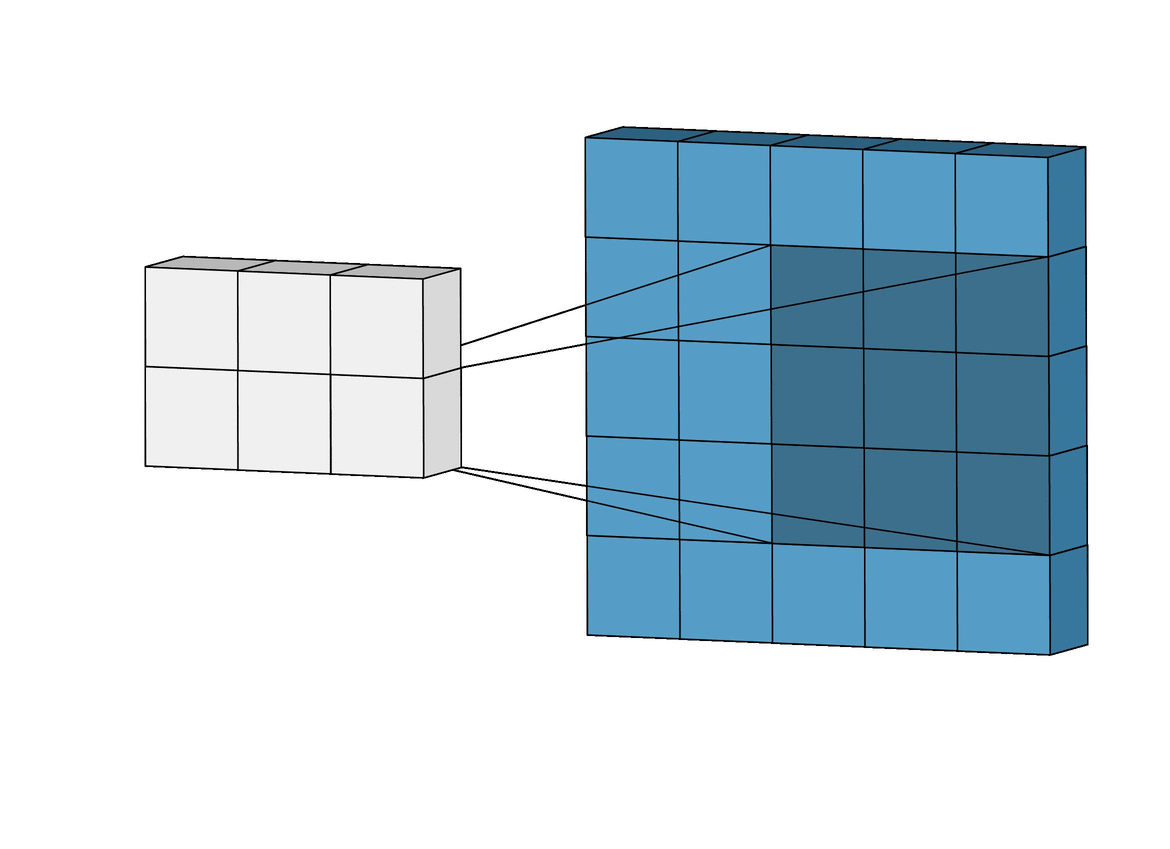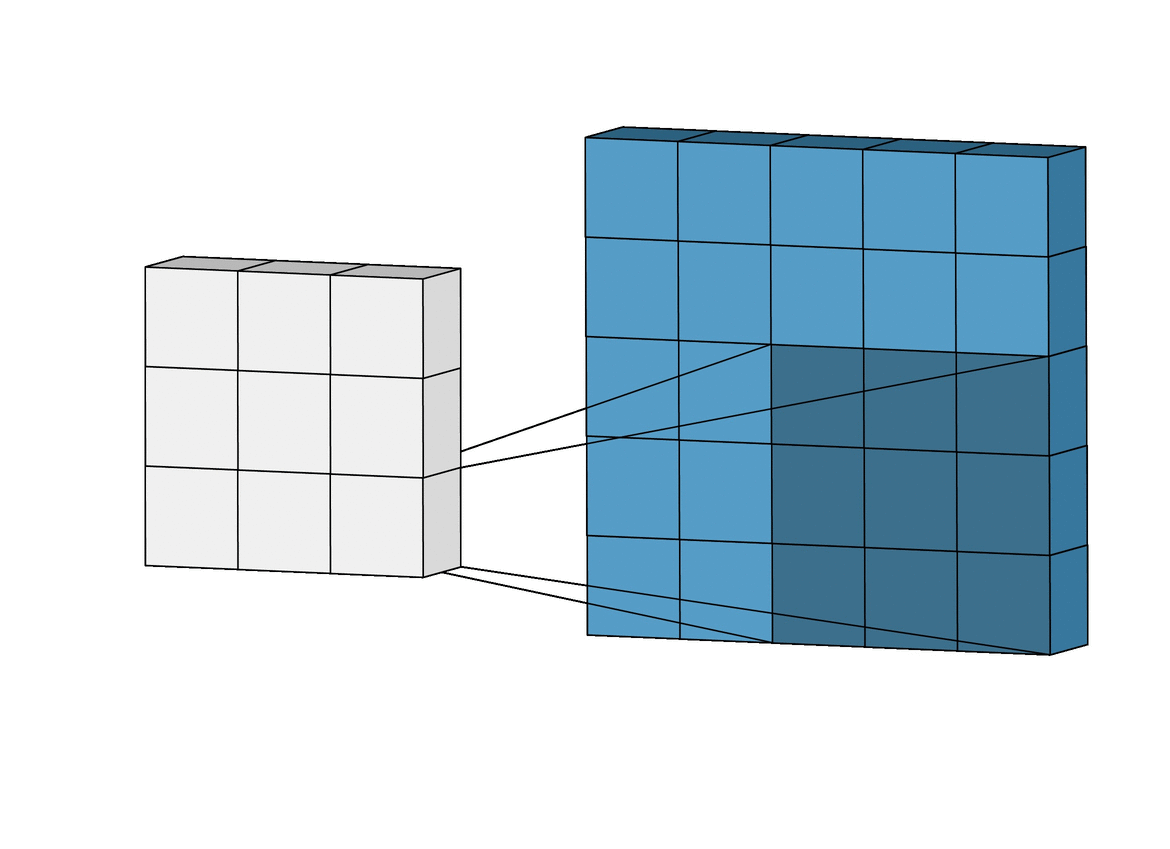
Wspomniane, istniejące od lat w grafice operacje korzystające z operacji konwolucji to przykładowo "sobel (top/bottom/left/right)", "blur", "emboss" - są to predefiniowane wartości w macierzach, które transformują obraz. Przykład - wybierając rozmiar macierzy transformującej 3 x3 można uzyskać:

Powyższa zrzut ekranu pochodzi ze strony, na której poeksperymentować można z wagami operacji konwolucji, jak również przeczytać wnikliwy opis (w j. ang.).
Parametry
Patrząc na animację w poprzednim punkcie intrygujące może okazać się to, że wynikowa macierz jest mniejsza niż wejściowe zdjęcie. Okazuje się, że operacja konwolucji jest parametrezowalna i można sterować jej zachowaniem. Omówię parametry dostępne przy budowie warstwy Conv2D w Keras (jak i analogicznie w innych frameworkach).
kernel_size - jest to długość i szerokość aplikowanej macierzy konwolucji
filters - aplikacja pojedynczej macierzy to tylko rozwiązanie teoretyczne - w rzeczystości obraz poddawany jest w każdej warstwie wielu operacjom konwolucji i wynik każdej z takich operacji zapisywany jest w osobnym kanale wyjściowym. filters określa liczbę tych kanałów.
padding - jest to określenie zasad dodawania marginesu so warstwy wejściowej tak by przykładowo: warstwa wyjściowa była dokładnie tej samej rozdzielczości.
strides - jest to określenie wartości kroku o jaki przesuwa się aplikowana macierz po źródłowym obrazie. Domyślnie 1 - przesuwa się zawsze o 1 piksel w prawo, a na końcu wiersza idzie do początku wiersza o 1 piksel niżej.
dilation_rate - odstęp pomiędzy wartościami aplikowanej macierzy, zwiększający obszar działania kosztem pomijania pewnych wartości; najlepiej zaprezentuje to poniższa wizualizacja:
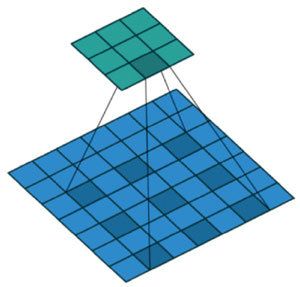
Implementacja
Definicja warstw sieci jest sekwencyjna, podobnie jak w poście "Binarna klasyfikacja obrazów":
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(8,3, input_shape= [96,96,3], activation='relu', padding='same'))
model.add(keras.layers.Conv2D(16,3, activation='relu', padding='same'))
model.add(keras.layers.Conv2D(32,3, activation='relu', padding='same'))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))Pojawiają się jednak trzy warstwy konwolucji (Conv2D).
Przyjęło się, że część sieci z operacjami konwolucji ( razem z innymi: Pooling i Normalizacji) nazywa się "feature extractors" (ekstrakcja cech). Część sieci w pełni połączona (Dense) nazywana jest "classificator" (klasyfikacja).
Wyniki
Po 150 epokach treningu z parametrami identycznymi jak w poście "Binarna klasyfikacja obrazów" otrzymać można:

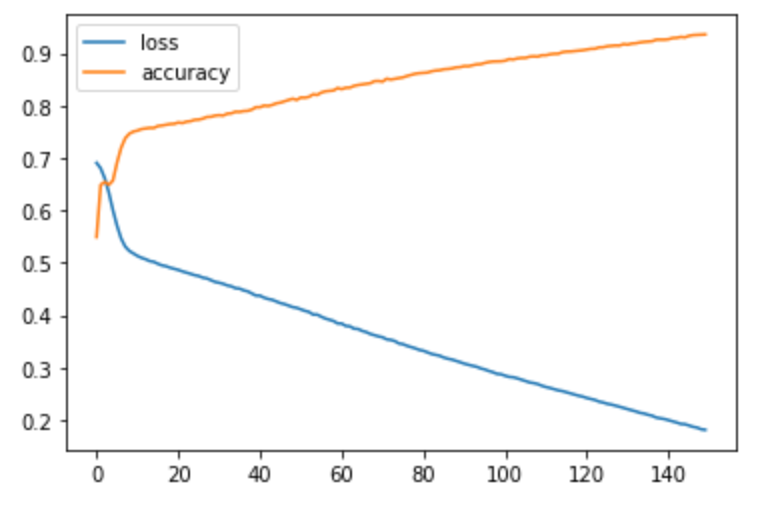
Celność (accuracy) na zbiorze treningowym to w tym przypadku 93.6% - całkiem nieźle. Jednakże nie jest to wynik któremu możemy ufać:
- trening przeprowadzony jest w sposób zakładający dostateczną ogólność zbioru treningowego
- nie wiadomo nadal czy zwiększenie liczby epok dałoby lepszy czy gorszy wynik "w rzeczywistości"
Co dalej?
Do tej pory przyglądaliśmy się jedynie wynikowi uzyskiwanemu przez zbiór treningowy. To podejście może prowadzić do poważnych problemów z naszym modelem. Następnym razem przyglądniemy się temu jak zaadresować właściwie ten temat.
Linki
- Interaktywne aplikowanie konwolucji na stronie:
https://setosa.io/ev/image-kernels/