
Prace nad polepszeniem wyników klasyfikacji sieci to nie tylko praca nad modelami czy architekturami sieci. Często znalezienie właściwego sposobu trenowania potrafi też przynieść polepszenie ostatecznych wyników klasyfikacji. Raz jest to sprytna funkcja kosztu, innym razem sposób obróbki danych. Dziś przyglądniemy się propozycji nauki sieci opublikowanej miesiąc temu przez specjalistów Google/DeepMind w pracy "Self-training with Noisy Student improves ImageNet classification".
Na rozwiązanie składa się kilka elementów:
- wyuczenie sieci trenera (Trainer)
- nadanie etykiet danym nieopisanym
- wyuczenie sieci ucznia (Student) wraz z augmentacją danych.
Sieć nauczyciela
Na zbiorze danych ImageNet wyuczona jest sieć nauczyciela z użyciem klasyfikatora EfficientNet. Dane serwowane są w niezmienionej formie do treningu.
Dodatkowe dane
Na nieoznaczonych danych ze zbioru ImageNet wygenerowane są pseudo-etykiety przez sieć nauczyciela. Nauczyciel generuje rozkłady prawdopodobieństwa przynależności do danych kategorii a nie pojedyncze kategorie
Trening sieci ucznia
Sieć ucznia trenowana jest z użyciem danych oryginalnych wymieszanych z danymi oznaczonymi przez sieć nauczyciela. Dane są augmentowane (poddawane drobnym transformacjom mającym na celu powiększenie zbioru uczącego i zapobiegnięcie zapamiętywaniu konkretnych cech) zgodnie z algorytmem 'RandAugment'. Dodatkowo przy treningu stosowane jest wyłączanie losowych wag podczas przetwarzania porcji danych (Dropout). Zabiegi te mają na celu zaszumienie danych, by zmusić siec ucznia do lepszej generalizacji.
Wyniki
Autorzy uzyskują niespotykaną dotąd wydajność klasyfikacji na zbiorze ImageNet TOP-1 87.4%. Poniższy wykres prezentuje porównanie sieci do innych popularnych modeli. Zaobserwować też można wpływ opisywanego procesu treningu na wyniki klasyfikacji architektur samych sieci EfficientNet:
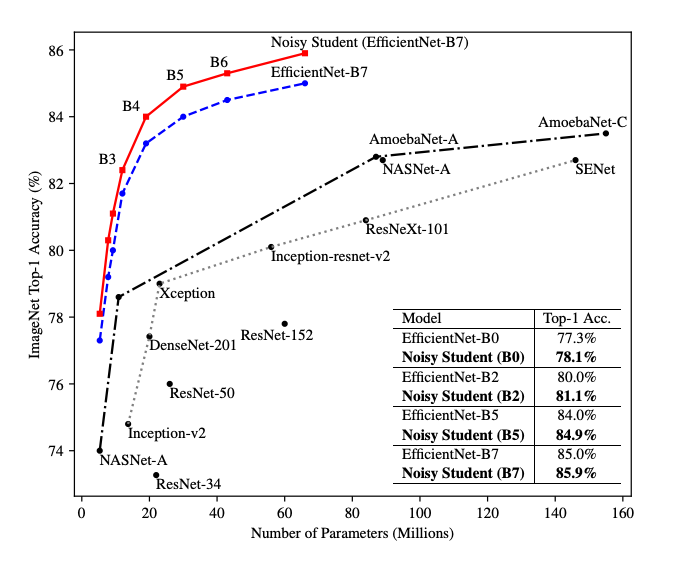
Po szczegóły zapraszam do oryginalnej pracy.
Użyteczność
Pytaniem pozostaje czy takie podejście łatwo przenieść do problemów mniej naukowych...
Nie zawsze dysponujemy bowiem reprezentatywnym dataset-em, który oznaczony jest w powiedzmy w 20%. Z drugiej strony rodzi to nowe możliwości: jeżeli mamy dane, które trzeba pooznaczać, kuszącą może okazać się opcja zmniejszenia liczności zbioru, na którym trzeba wykonać tę żmudną, manualną część pracy...