
Stary, wyświechtany, ale nieustannie używany dataset do Computer Vision trafia dziś do posta. Dla tych, którzy go nie znają po krotce opiszę co zawiera. Pokażę też jak najszybciej rozpocząć prace z nim w jupyter notebook-u.
Dataset to zbiór danych to treningu czy walidacji w machine learning-u. Część z nich może być "o-label-owanych" a część nie. Co to znaczy? Jeżeli dostarczone dane (tutaj obrazki) powiązane są w zbiorze danych z jakąś pożądaną własnością, mówimy że posiadamy "labeled data". Dzięki temu nie musimy oznaczać danych sami, mając komplet danych do nauki modeli ("wejście" i "wyjście").
[Ten post jest fragmentem serii "Krok po kroku" wprowadzającej do uczenia maszynowego (Machine Learning). Zapraszam do zapoznania się z całością.]
Zawartość dataset-u
MNIST to zbiór 70'000 obrazów (60'000 treningowych i 10'000 testowych) w skali szarości, każdy o rozdzielczości 28x28 pikseli przedstawiające różne wersje ręcznie napisanych cyfr (0-9). Każdy z obrazów powiązany jest z wartością liczbową będącą równą cyfrze, którą obraz przedstawia. Oto kilka przykładów:

Jest to zbiór o tyle przyjemny, że :
- jest mały, bo mieści się cały w pamięci
- w sposób szybki da się na nim testować różne koncepcje (większe datasety potrzebują wielokrotnie więcej zasobów)
Pobieranie dataset-u
Jeżeli nie masz skonfigurowanego środowiska do pracy z Python-em (w tym jupyter notebook-a) zapraszam do opisu instrukcji instalacji.
Najprostszą metodą pobierania i pracy z datasetem, jaką udało mi się znaleźć jest instalacja pakietu "python-mnist". W oknie konsoli zatem wpisać musimy polecenie:
pip install python-mnistZe względów licencyjnych dane datasetu, należy pobrać z oryginalnej strony. Na szczęście dokumentacja pakietu python-mnist przychodzi to z pomocą. Pokazuje zautomatyzowany sposób pobierania dataseto, do którego potrzebujemy jednak mieś w swoim środowisku klienta git (systemu wersjonowania plików tekstowych). Dla tych, którzy nie mają git-a, komenda która go zainstaluje w Ubuntu to:
sudo apt-get install gitPotem należy sklonować repozytorium kodu, które zawiera skypt pobierający dataset:
git clone https://github.com/bwosh/python-mnist.gitwchodzimy do stworzonego katalogu:
cd python-mnisti uruchamiamy pobieranie plików:
./get_data.shpo wykonaniu tem operacji w podkatalogu 'data' powinny znaleźć się pliki:
t10k-images-idx3-ubyte
t10k-labels-idx1-ubyte
train-images-idx3-ubyte
train-labels-idx1-ubyte
Nazwy plików i format ich przechowywania mogą wydawać się magiczne, niemniej zainstalowany wcześniej pakiet pythona zajmie się wydobyciem danych do bardziej używalnej formy.
Zobaczmy to w kodzie
Po uruchomieniu jupyter notebooka, wpiszmy poniższy kod:
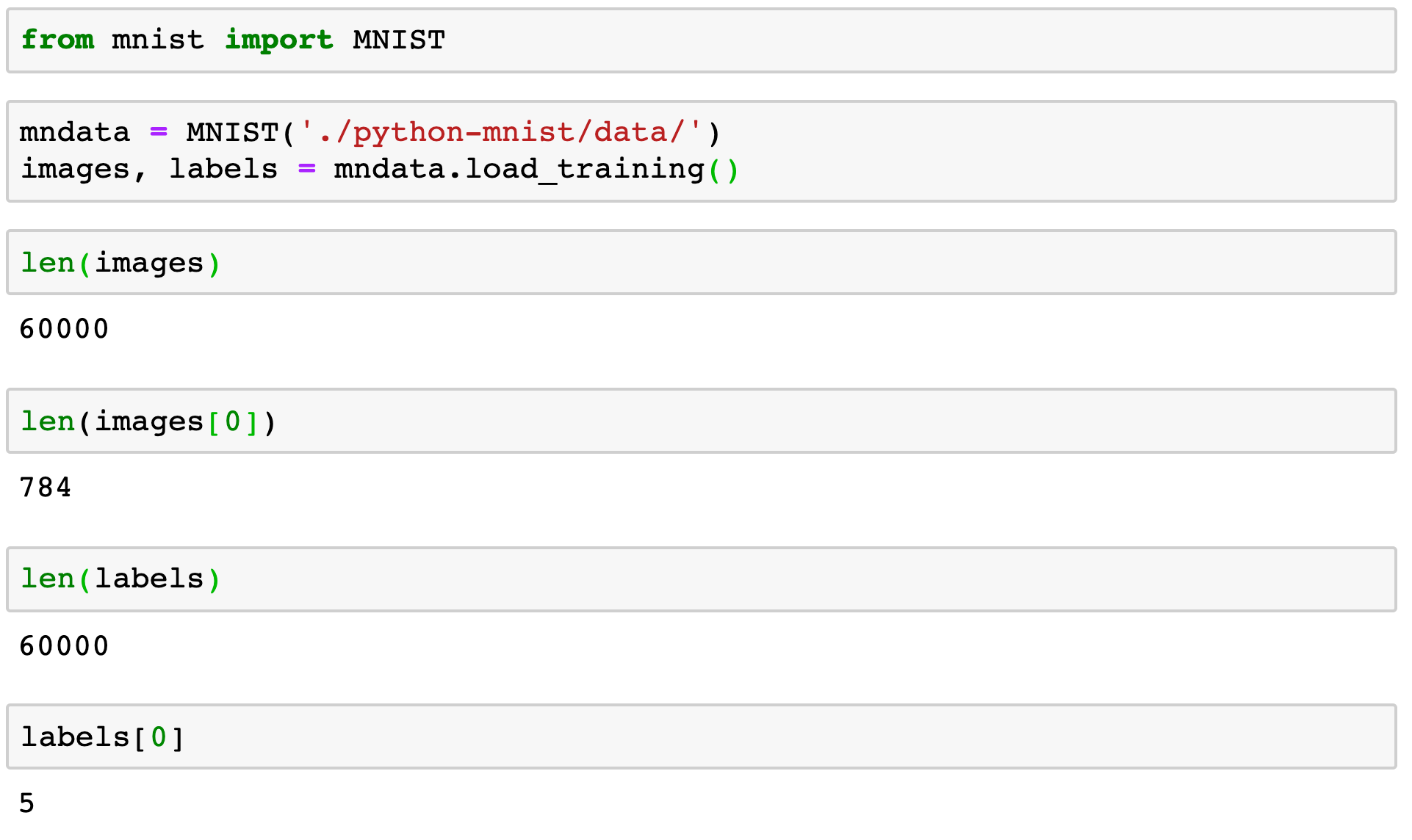
from mnist import MNIST
mndata = MNIST('./python-mnist/data/')
images, labels = mndata.load_training()Kod ten importuje bibliotekę i przygotowuje dwie kolekcje:
- listę obrazów jako wektory o długości 784, każdy z wartością 0-255
- listę wartości równych prezentowanej cyfrze
Aby zwizualizować cyfry należy dokonać jeszcze kilku czynności:
- zaimportować bibliotekę wyświetlającą obrazy
- zaimportować bibliotekę numeryczną
- przekształcić obraz z wektora 784 to macierzy 28x28
- wyświetlić obraz z skali szarości
W kolejnej komórce jupyter notebooka napiszmy:
import matplotlib.pyplot as plt
import numpy as np
# Konwersja do typu np.ndarray
sample_image = np.array(images[0])
# Zmiana rozdzielczości do 28x28
sample_image = sample_image.resize(28,28)
# Dopasowanie wielkości wykresu
plt.figure(figsize=(2,2))
# Wyłączenie opisów osi X i Y
plt.axis('off')
# Pozakanie obrazu w skali szarości
plt.imshow(sample_image, cmap='gray') Po uruchomieniu zobaczymy:
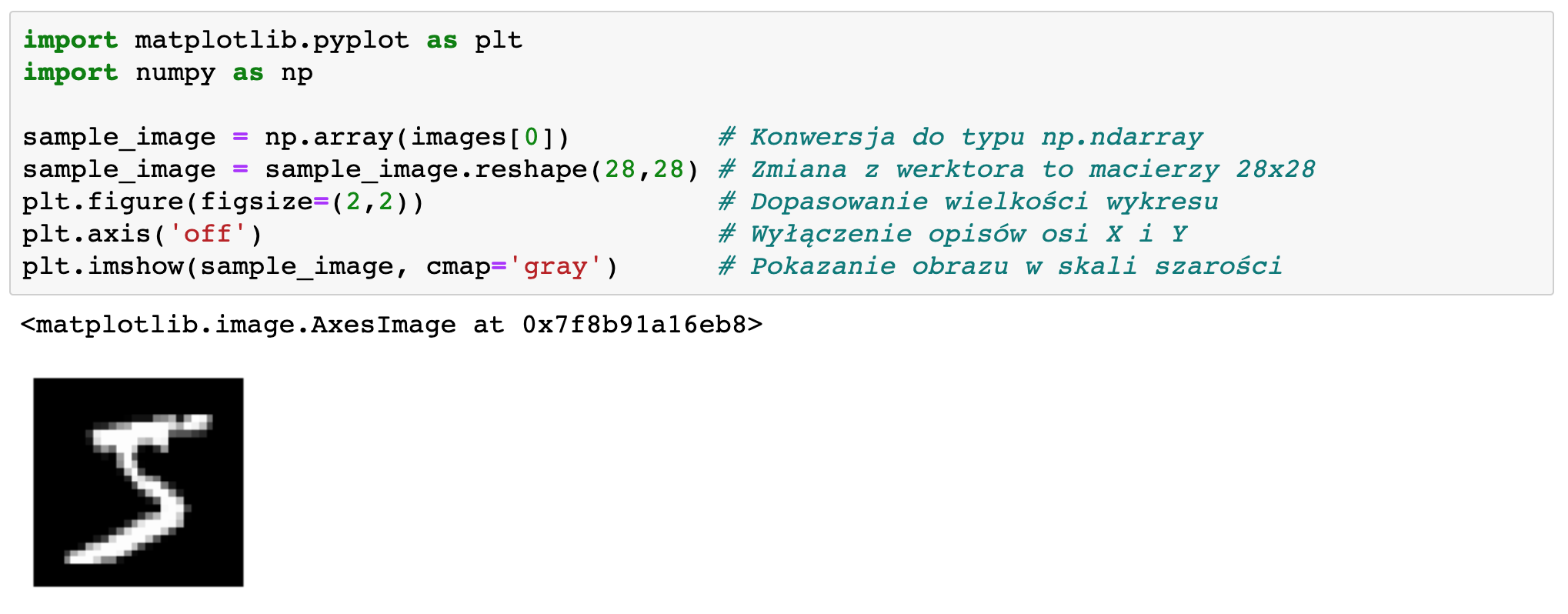
Od tego momentu można zacząć jakieś konkretne prace z datasetem, ale o tym innym razem....